Microservice URL Shortener – Production‑minded portfolio build
I built a microservice‑based URL shortener to practice production disciplines on a small, approachable system. It focuses on clear service boundaries, predictable deploys, observability, and developer ergonomics.
- Services: shortener, redirect, analytics, frontend, edge (NGINX)
- Data: PostgreSQL (primary), Redis cache, file/"mock" DB for fast local dev
- Platform: Docker Compose for dev, Kubernetes manifests for prod‑like deploys, Terraform scaffolding for cloud
- Observability: Prometheus + Grafana (pre‑provisioned dashboard)
- Why: Demonstrate practical system design trade‑offs in a compact codebase

Project goals
- Model a realistic, maintainable microservice system without over‑engineering
- Keep local development fast and deterministic
- Make runtime behavior visible (latency, errors, cache hit ratio)
- Provide an incremental path from laptop → Compose → Kubernetes → Cloud
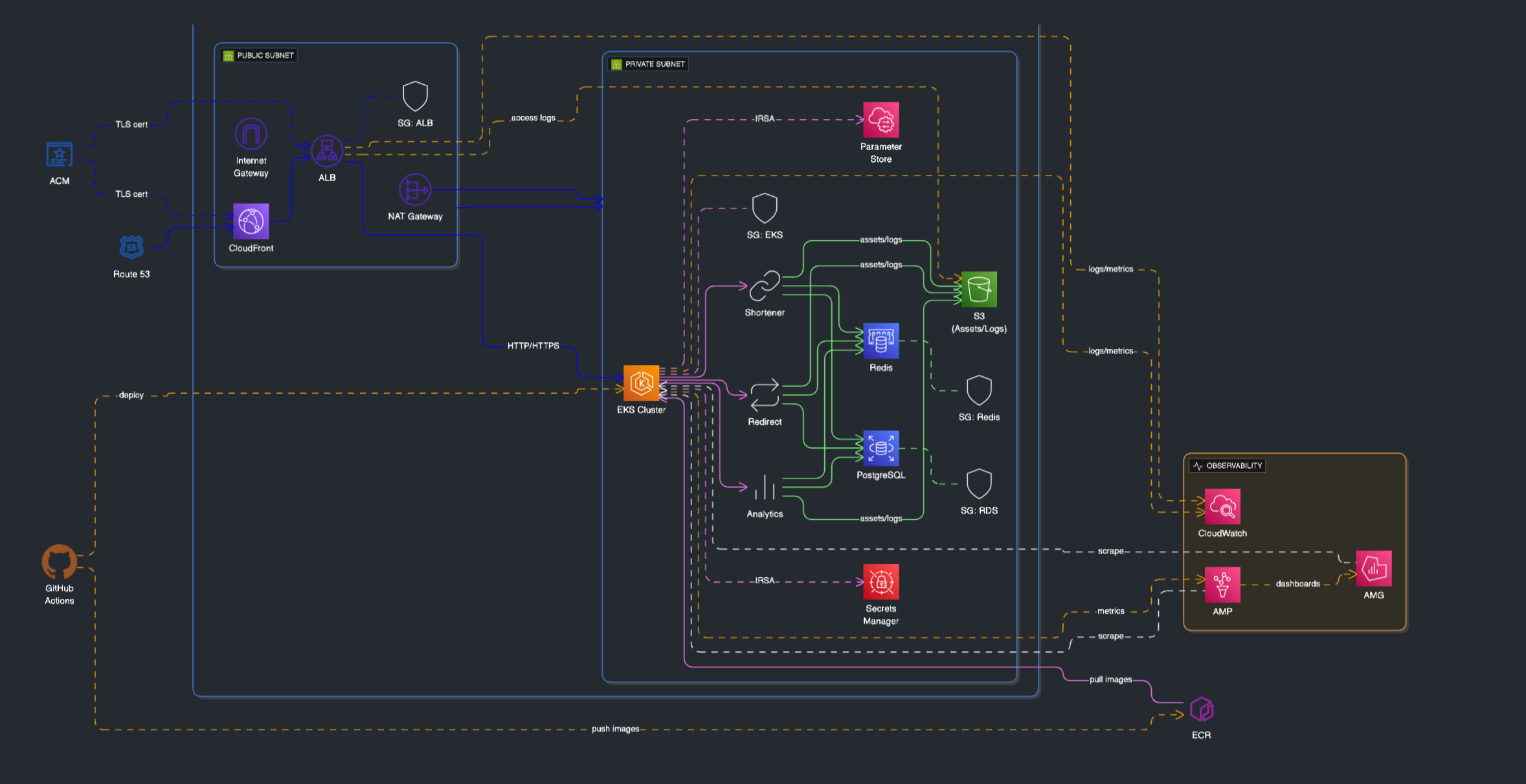
Architecture overview
- Shortener Service
- Validates incoming long URLs, generates collision‑resistant short codes
- Persists mappings to PostgreSQL and warms Redis cache
- Exposes REST endpoints for shorten and metadata
- Redirect Service
- Resolves short code → long URL with hot‑path caching in Redis
- Responds with efficient 301/302 redirects and registers a click event
- Designed for extremely low latency and minimal I/O on cache hit
- Analytics Service
- Accepts click events (ip, user agent, referer optionally)
- Aggregates counts and exposes time‑bucketed summaries
- Performs lightweight input validation and backpressure handling
- Frontend
- Minimal SPA with Tailwind; small, frictionless UX for creating and previewing links
- Served behind NGINX; can be fronted by Kubernetes Ingress in cluster
- Edge / Gateway
- NGINX reverse proxy locally; Ingress controller in Kubernetes
- Central place for CORS, rate limiting, caching headers, and routing

Data model (essentials)
urls(id, short_code, long_url, created_at, owner_id?)clicks(id, short_code, ts, ip?, user_agent?, referer?)
Indexes:
urls.short_codeuniqueclicks.short_code+ time index for fast aggregations
API surface (concise)
POST /api/shorten→{ longUrl }→{ shortCode, url }GET /r/:shortCode→ 301/302 tolongUrl(served by Redirect)POST /api/analytics/click→ event ingest (called by Redirect asynchronously)GET /api/analytics/summary?from&to&granularity→ aggregates
Request lifecycle
- Client calls Shortener to create a short link → validates URL → stores in Postgres → sets Redis key (
shortCode → longUrl) → returns short URL. - User follows short URL → Redirect checks Redis. On cache hit, immediate redirect and async click log; on miss, reads Postgres, refreshes cache, then redirects.
- Analytics ingests click events and exposes summaries for dashboard and UI.
Operational concerns
- Local development: Docker Compose spins up services + Postgres + Redis + Prometheus + Grafana quickly. Mock DB/Redis adapters speed up unit testing.
- Kubernetes:
k8s/contains Deployments, Services, Ingress, Secrets, and a Postgres StatefulSet. Manifests are minimal but production‑minded (readiness, resources, env). - Terraform:
infra/terraformprovides a base to stand up cloud infra; intentionally lean so it can be adapted to the target provider. - NGINX: Edge config centralizes cross‑cutting concerns (compression, security headers, caching rules).
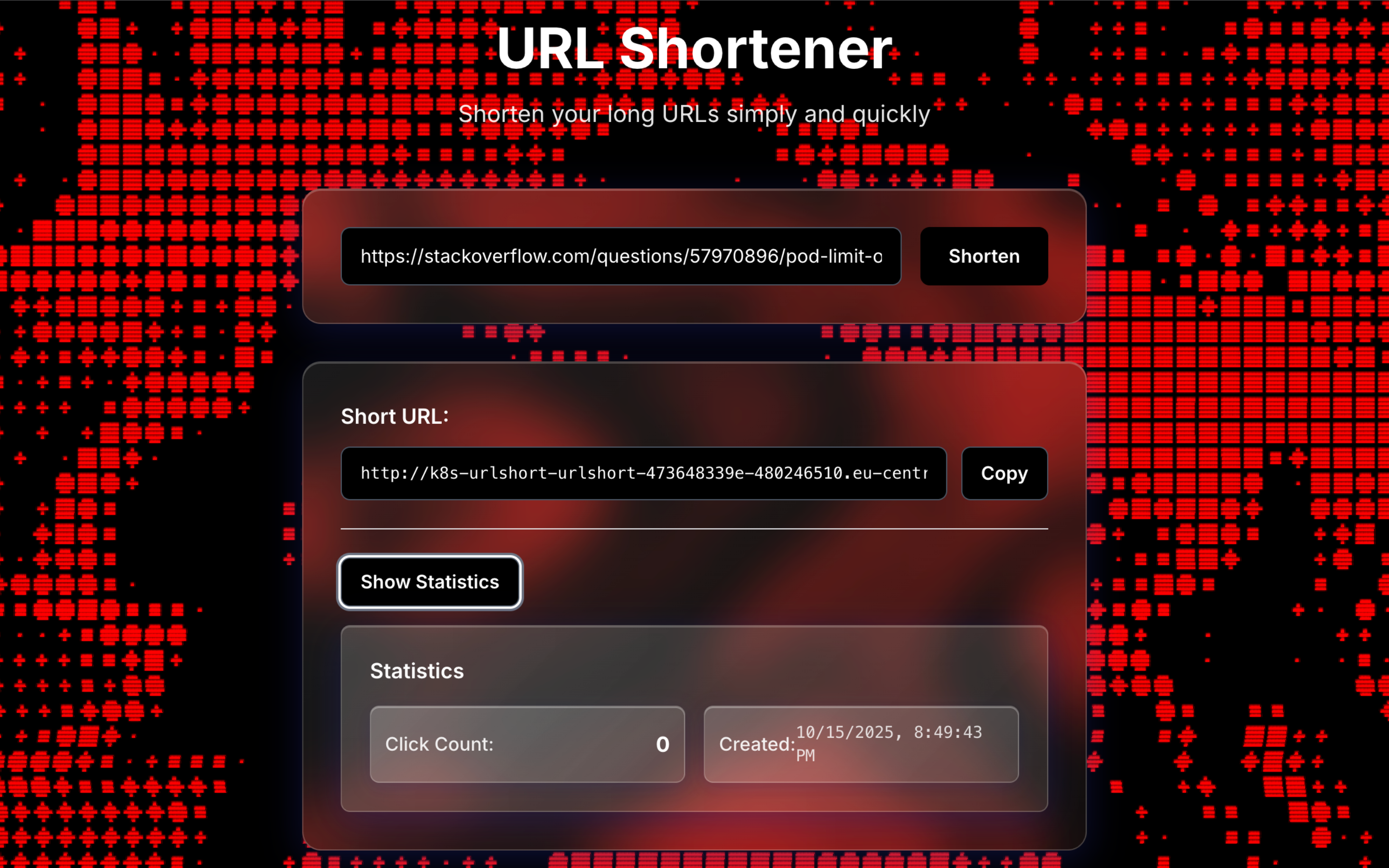
Observability
- Metrics: request duration histograms, redirect outcome counts, cache hit ratio, and click throughput.
- Prometheus: central scrape config in
monitoring/prometheus.yml. - Grafana: dashboard provisioned from
monitoring/grafana/dashboards/url-shortener-dashboard.json. - Dashboards highlight:
- p50/p95/p99 request latency per service
- redirect success vs. failure
- cache hit ratio trend
- clicks over time (time‑bucketed)
Security and reliability
- Input validation: strict URL and short‑code validation to avoid SSRF/XSS vectors.
- Secrets: Kubernetes Secret objects for credentials; env‑driven config for local.
- Transport: designed to sit behind TLS at the edge (Ingress/NGINX).
- Rate limiting: configured at the edge to protect public endpoints.
- Graceful shutdown: services observe termination signals; readiness probes avoid serving when not ready.
Performance notes
- Redirect is optimized around cache hits; the hot path avoids DB access entirely.
- Cache keys use explicit expirations; background refresh avoids thundering herd.
- Short code generation targets low collision probability while remaining readable.
- Simple batching in Analytics reduces write amplification under bursts.
Trade‑offs and decisions
- Kept the service boundary small and opinionated to reduce complexity.
- Chose Postgres over NoSQL to keep joins and constraints simple.
- Added mock adapters so tests and demos are fast even without full infra.
- Prefer explicit configuration over magic defaults to improve operability.
Running the project
- Local:
docker compose up(includes DB, cache, monitoring). Environment values can be copied fromenv.example. - Kubernetes: apply manifests in
k8s/(namespace → secrets → statefulset → services → deployments → ingress). - Observability: visit Grafana; the URL and credentials depend on your local/cluster setup.
Edge cases considered
- Non‑HTTP(s) URLs rejected early.
- Expired or deleted short codes return a clear 404 contract from Redirect.
- Cache stampede avoided via single‑flight read + short TTLs.
- Analytics ingestion backpressure with bounded queue and retries.
Future work
- Background link health checks and automatic disablement
- Per‑link rate limits and owner‑level quotas
- Signed admin APIs with audit logs
- Event streaming pipeline (e.g., Kafka) for analytics at larger scale
- Multi‑region redis/DB strategy for global latency reduction
Notes
This repository is intentionally small, but the patterns (service boundaries, deploy flow, and observability) mirror how I build larger systems. If you want me to tailor the content (e.g., screenshots, live demo links, or a deeper cost/perf breakdown), I can extend this page accordingly.
Service SLOs (targets)
- Redirect: 99.9% avail; p95 latency ≤ 50 ms (cache hit), ≤ 200 ms (miss)
- Shortener: 99.9% avail; p95 latency ≤ 200 ms
- Analytics ingest: 99.5% avail; 99% events visible in ≤ 60 s
SLOs are observable via Prometheus histograms and error ratios; alerts wired on burn‑rate.
Autoscaling and capacity
- HPA on Redirect and Shortener by CPU and request latency (custom metrics)
- Redis sized for hot set with eviction policy; keys TTL tuned for traffic shape
- Postgres connection pooling (e.g., pgbouncer) recommended beyond single instance
CI/CD and releases
- Build and test on each commit → push images to registry → progressive rollout
- Kubernetes: rolling updates with maxUnavailable=0, readiness gates on startup
- Canary option via header‑based routing at edge; automated rollback on SLO burn
Security hardening
- Strict CORS and content security policy at NGINX/Ingress
- Rate limiting per IP and per short code to mitigate abuse
- Secrets via K8s Secrets; rotate regularly; non‑root containers, read‑only FS where possible
- Optional allow‑list for admin/metrics endpoints; auth tokens with short TTL
Testing strategy
- Unit tests around validators, code generation, caching logic (mock Redis/DB)
- Integration tests for redirect hot/miss paths and analytics ingest
- Load tests to validate cache hit ratio and DB headroom before releases
Resilience and DR
- Postgres backups with PITR; restore runbooks validated
- Redis persistence (AOF) optional; cache can be rebuilt from DB
- Health probes + circuit breakers around DB/Redis; exponential backoff on retries
Cost and footprint
- Compose for cheap demos; single‑node K8s for previews; scale out only when needed
- Cache hit ratio is the main lever for cost vs. latency; dashboard tracks this explicitly
Notes
This repository is intentionally small, but the patterns (service boundaries, deploy flow, and observability) mirror how I build larger systems. If you want me to tailor the content (e.g., screenshots, live demo links, or a deeper cost/perf breakdown), I can extend this page accordingly.